12.1 멀티 스레드 개념
12.1.1 프로세스와 스레드
프로세스?
- 실행 중인 하나의 프로그램
: 하나의 프로그램은 다중 프로세스를 만들기도 함
멀티 태스킹?
: 두 가지 이상의 작업을 동시에 처리하는 것
- 멀티 프로세스: 독립적으로 프로그램을 실행하고 여러 가지 작업 처리
- 멀티 스레드: 한 개의 프로그램을 실행하고 내부적으로 여러 가지 작업 처리

12.1.2. 메인스레드
- 모든 자바 프로그램은 메인 스레드가 main()메소드를 실행하면서 시작됨
- main() 메소드의 첫 코드부터 아래로 순차적으로 실행함
- main() 메소드의 마지막 코드를 실행하거나, return 문을 만나면 실행이 종료됨
- 코드의 실행 흐름 → 스레드
메인 스레드는 작업 스레드를 만들어서 병렬로 코드를 실행할 수 있음
즉, 멀티 스레드를 생성해서 멀티 태스킹을 수행함

프로세스의 종료
- 싱글 스레드: 메인 스레드가 종료하면 프로세스도 종료됨
- 멀티 스레드: 실행 중인 스레드가 하나라도 있다면, 프로세스는 종료되지 않음
12.2 작업 스레드 생성과 실행
- 몇 개의 작업을 병렬로 실행할지 결정
12.2.1 Thread 클래스로부터 직접 생성
class Task implements Runnable {
public void run() {
스레드가 실행할 코드;
}
}12.2.2 Thread 하위 클래스로부터 생성
public class WorkerThread extends Thread {
@Override
public void run() {
// 스레드가 실행할 코드
}
}
thread thread = new WorkerThread();Thread thread = new Thread() {
public void run() {
스레드가 실행할 코드;
}
};12.2.3. 스레드의 이름
- 메인 스레드 이름: main
- 작업 스레드 이름: Thread-n
thread.getName();- 작업 스레드의 이름 변경
thread.setName("스레드 이름");- 코드를 실행하는 스레드의 참조 얻기
Thread thread = Thread.currentThread();12.3. 스레드 우선 순위
- 동시성
: 멀티 작업을 위해 하나의 코어에서 멀티 스레드가 번갈아 가며 실행하는 성질
- 병렬성
: 멀티 작업을 위해 멀티 코어에서 개별 스레드를 동시에 실행하는 성질
스레드 스케쥴링
스레드의 개수가 코어의 수보다 많을 경우
- 스레드 스케쥴링?
:스레드를 어떤 순서로 동시성으로 실행할 것인가를 결정하는 것
- 스레드 스케쥴링에 의해 스레드들은 번갈아 가면서 그들의 run() 메소드를 조금씩 실행

자바의 스레드 스케쥴링
우선순위 방식과 순환 할당 방식을 사용
우선순위 방식(코드로 제어 가능)
: 우선 순위가 높은 스레드가 실행 상태를 더 많이 가지도록 스케쥴링하는 방식
순환 할당 방식(코드로 제어할 수 없음)
: 시간 할당량을 정해서 하나의 스레드를 정해진 시간만큼 실행하는 방식
스레드 우선 순위
- 스레드들이 동시성을 가질 경우, 우선적으로 실행할 수 있는 순위
- 우선 순위는 1(낮음)에서부터 10(높음)까지로 부여
: 모든 스레드들은 기본적으로 5의 우선 순위를 할당
우선 순위 효과
- 싱글 코어의 경우
: 우선 순위가 높은 스레드가 실행 기회를 더 많이 가지기 때문에 우선 순위가 낮은 스레드보다 계산 작업을 빨리 끝냄
- 멀티 코어의 경우
: 쿼드 코어 경우에는 4개의 스레드가 병렬성으로 실행될 수 있기 때문에, 4개 이하의 스레드를 실행할 경우, 우선 순위 방식은 크게 영향을 미치지 못함
: 최소한 5개 이상의 스레드가 실행되어야 우선 순위의 영향을 받음
12.4 동기화 메소드와 동기화 블록
12.4.1 공유 객체를 사용할 때의 주의할 점
- 멀티 스레드가 하나의 객체를 공유하므로 해서 생기는 오류
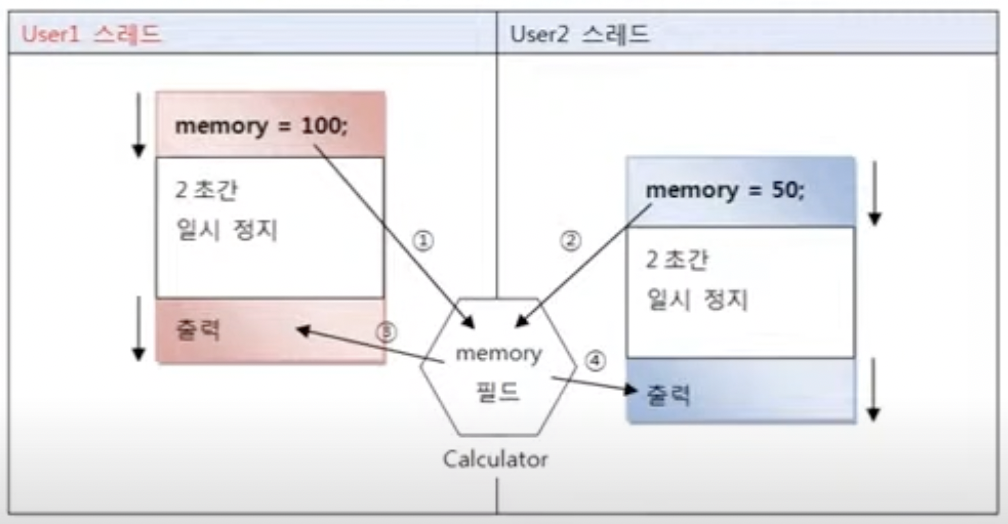
12.4.2. 동기화 메소드 및 동기화 블록
- 공유 객체를 사용할 때의 문제점을 해소할 수 있음
- 단 하나의 스레드만 실행할 수 있는 메소드 또는 블록을 말함
- 다른 스레드는 메소드나 블록 실행이 끝날 때까지 대기해야 함
동기화 메소드
public synchronized void method() {
임계 영역;
}
동기화 블록
public void method() {
synchronized(공유 객체) {
임계영역
}
}12.5 스레드 상태
| 상태 | 열거 상수 | 설명 |
| 객체 생성 | NEW | 스레드 객체가 생성, 아직 start() 메소드가 호출되지 않은 상태 |
| 실행 대기 | RUNNABLE | 실행 상태로 언제든지 갈 수 있는 상태 |
| 일시 정지 | BLOCKED | 사용하고자 하는 객체의 락이 풀릴 때까지 기다리는 상태 |
| WAITING | 다른 스레드가 통지할 때까지 기다히는 상태 | |
| TIMED_WAITING | 주어진 시간 동안 기다리는 상태 | |
| 종료 | TERMINATED | 실행을 마친 상태 |
12.6 스레드 상태 제어
상태 제어
- 실행 중인 스레드의 상태를 변경하는 것을 말함
- 상태 변화를 가져오는 메소드의 종류
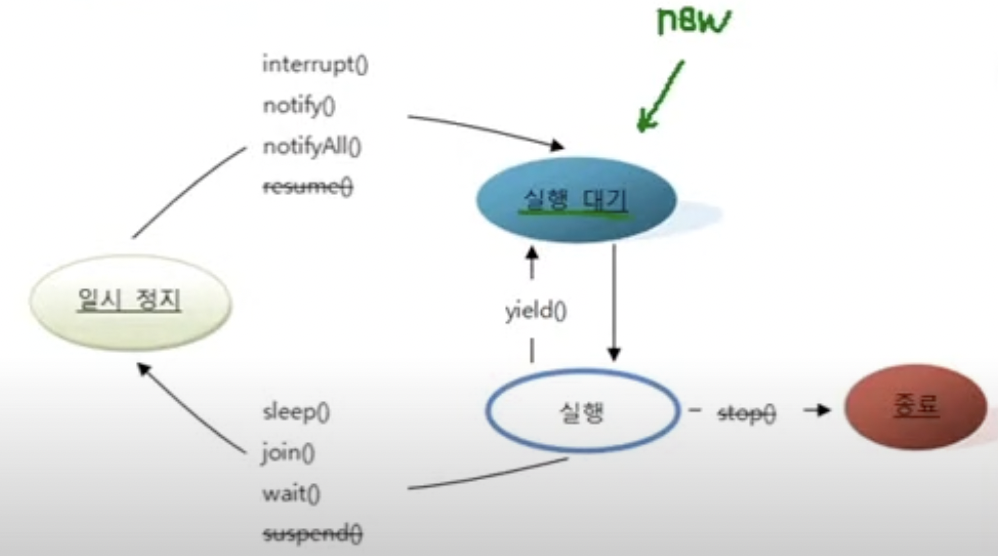
12.6.1 주어진 시간동안 일시 정지 sleep()
12.6.2 다른 스레드에게 실행 양보 yield()
12.6.3 다른 스레드의 종료를 기다림 join()
12.6.4 스레드 간 협업 wait(), notify(), notifyAll()
12.6.5 스레드의 안전한 종료 stop플래그, interrupt()
12.7 데몬 스레드
- 주 스레드의 작업을 돕는 보조적인 역할을 수행하는 스레드
- 주 스레드가 종료되면 데몬 스레드는 강제적으로 자동 종료
: 워드프로세서의 자동저장, 미디어플레이어의 동영상 및 음악 재생, 가비지 컬렉터
- 데몬스레드 설정
: 주 스레드가 데몬이 될 스레드의 setDeamon(true)를 호출
: 반드시 start() 메소드 호출 전에 setDaemon(true)를 호출해야 함
: 그렇지 않으면 IllegalThreadException이 발생
- 데몬 스레드 확인 방법
: isDaemon() 메소드의 리턴값을 조사
12.8 스레드 그룹
스레드 그룹
- 관련된 스레드를 묶어서 관리할 목적으로 이용
- 스레드 그룹은 계층적으로 하위 스레드 그룹을 가질 수 있음
자동 생성되는 스레드 그룹
: system 그룹: JVM 운영에 필요한 스레드들을 포함
: system/main 그룹 - 메인 스레드를 포함
스레드는 반드시 하나의 스레드 그룹에 포함
: 기본적으로 자신을 생성한 스레드와 같은 스레드 그룹에 속하게 됨
: 명시적으로 스레드 그룹에 포함시키지 않으면 기본적으로 system/main 그룹에 속함
스레드 그룹 이름 얻기
ThreadGroup group = Thread.currentThread.getThreadGroup();
String groupName = group.getName();12.9 스레드풀
스레드 폭증
- 병렬 작업 처리가 많아지면 스레드의 개수가 증가
- 스레드 생성과 스케쥴링으로 인해 CPU가 바빠지고, 메모리 사용량이 늘어남
- 따라서 애플리케이션의 성능이 급격히 저하됨
스레드 풀
- 작업 처리에 사용되는 스레드를 제한된 개수만큼 미리 생성
- 작업 큐에 들어오는 작업들을 하나씩 스레드가 맡아서 처리함
- 작업 처리가 끝난 스레드는 작업 결과를 애플리케이션으로 전달
- 스레드는 다시 작업큐에서 새로운 작업을 가져와 처리함
ExecutorService 인터페이스와 Executor 클래스
- 스레드 풀을 생성하고 사용할 수 있도록 java.util.concurrent 패키지에서 제공
- Executors의 정적 메소드를 이용해서 ExecutorService 구현 객체 생성
- 스레드 풀 = ExecutorService 객체
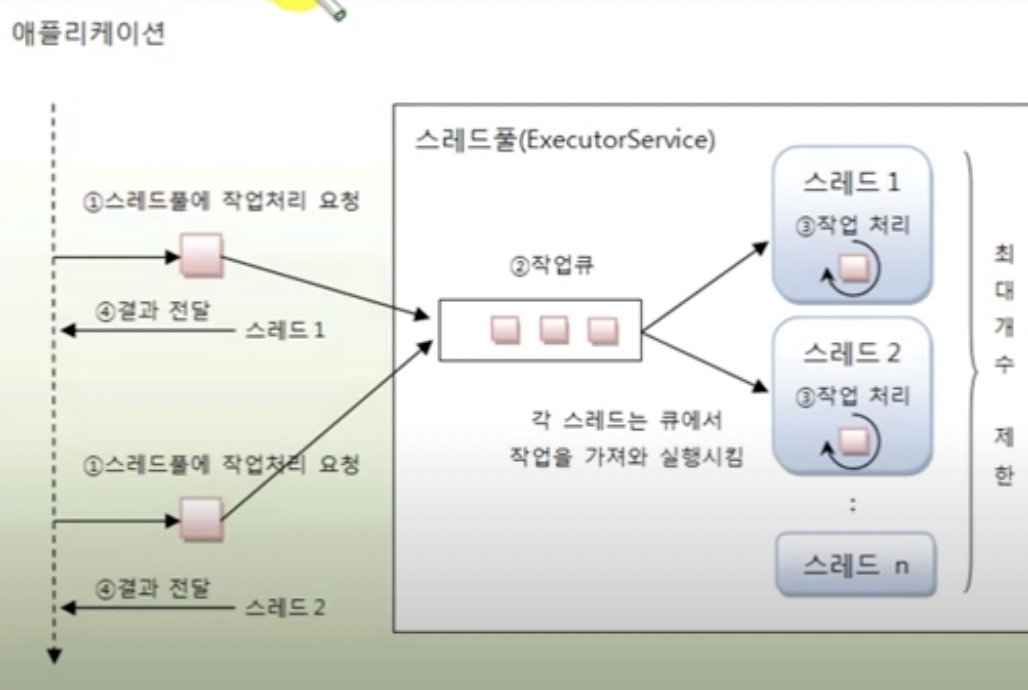
스레드풀 생성
: 다음 두 가지 메소드 중 하나로 간편 생성
| 메소드명(매개변수) | 초기 스레드 수 | 코어 스레드 수 | 최대 스레드 수 |
| newCachedThreadPool() | 0 | 0 | Integer.MAX_VALUE |
| newFixedThreadPool(int nThreads) | 0 | nThreads | nThreads |
코어 스레드 수: 제거하지 않고 유지해야 하는 최소한의 스레드 수
newCachedThreadPool()
- int 값이 가질 수 있는 최대 값만큼 스레드가 추가되나, 운영체제의 상황에 따라 달라짐
- 1개 이상의 스레드가 추가되었을 경우 (작업량이 줄거나~),
60초 동안 추가된 스레드가 아무 작업을 하지 않으면 추가된 스레드를 종료하고 풀에서 제거함
newFixedThreadPool(int nThreads)
- 코어 스레드 개수와 최대 스레드 개수가 매개값으로 준 nThread
- 스레드가 작업을 처리하지 않고 놀고 있더라도, 스레드 개수가 줄지 않음
ThreadPoolExecutor을 이용한 직접 생성
- 앞의 두 메소드가 내부적으로 생성
- 스레드의 수를 자동으로 관리하고 싶을 경우 직접 생성해서 사용함
스레드풀 종료
스레드풀의 스레드는 기본적으로 데몬 스레드(주 스레드가 종료되면 자동적으로 종료되는 것)가 아님
: 메인 스레드가 종료되더라도 스레드풀의 스레드는 작업을 처리하기 위해 계속 실행되므로 애플리케이션은 종료되지 않음
: 따라서, 스레드풀을 종료해서 모든 스레드를 종료시켜야 함
스레드풀 종료 메소드
1. shutdown()
: 현재 처리 중인 작업뿐만 아니라, 작업큐에 대기하고 있는 모든 작업을 처리한 뒤 스레드풀 종료시킴
2. shutdownNow()
: 현재 작업 처리 중인 스레드를 interrupt해서 작업 중지를 시도하고 스레드풀을 종료시킴
: 리턴값은 작업큐에 있는 미처리된 작업의 목록
: 가급적이면 안 사용하는 것이 좋음
3. awaitTermination(long timeout, TimeUnit unit)
: shutdown() 메소드 호출 이후, 모든 작업 처리를 타임아웃 시간 내에 완료하면 true를 리턴
: 완료하지 못하면 작업 처리 중인 스레드를 중지 시킨 뒤 false리턴
작업 생성
- 하나의 작업은 Runnable 또는 Callable 객체로 표현함
- 둘의 차이점?
: 작업 처리 완료 후 리턴값의 존재 유무 (Callable이 리턴값이 있음)
- 스레드풀에서 작업 처리
: 작업 큐에서 객체를 가져와 스레드로 하여금 run()과 call() 메소드를 실행하도록 하는 것
작업 처리 요청
- 작업큐에 러너블 또는 콜러블 객체를 넣는 행위
- 작업 처리 요청을 위해 다음 두 가지 종류의 메소드를 제공함
1. execute
: 러너블 작업 큐에 저장
: 작업 처리 결과를 받지 못함
2. submit
: 러너블 또는 콜러블을 작업큐에 저장
: 리턴 Future을 통해 작업 처리 결과를 얻을 수 있음
- 작업 처리 도중 예외가 발생할 경우?
1. execute
: 스레드 자체가 종료되고, 해당 스레드는 제거됨
따라서, 스레드풀은 다른 작업 처리를 위해 새로운 스레드를 생성함
2. submit
: 스레드가 종료되지 않고 다음 작업을 위해 재사용 됨
블로킹 방식의 작업 완료 통보 받기
블로킹 방식?
: 무언가를 요청하고 난 뒤 요청의 결과가 올 때까지 기다리는 방식
Future
- submit의 리턴값
- 작업 결과가 아니라 지연 완료 객체
- 작업이 완료될 때까지 기다렸다가 최종 결과를 얻기 위해서 get() 메소드 사용
1. get()
: 작업이 완료될 때까지 블로킹되었다가 처리 결과를 리턴
2. get(long timeout, TimeUnit unit)
: timeout 시간동안 작업이 완료되면 결과 리턴, 완료되지 않으면 TimeoutException을 발생시킴
- Future의 get()은 UI스레드에서 호출하면 안됨
: UI를 변경하고 이벤트를 처리하는 스레드가 get() 메소드를 호출하면
작업을 완료하기 전까지는 UI를 변경할 수도 없고 이벤트도 처리할 수 없음
- 다른 메소드
| 리턴 타입 | 메소드명(매개변수) | 설명 |
| boolean | cancel(boolean mayInterruptIfRunning) | 작업 처리가 진행 중일 경우 취소 시킴 |
| boolean | isCancelled() | 작업이 취소되었는지 여부 |
| boolean | isDone() | 작업 처리가 완료되었는지 여부 |
작업 처리 결과를 외부 객체에 저장
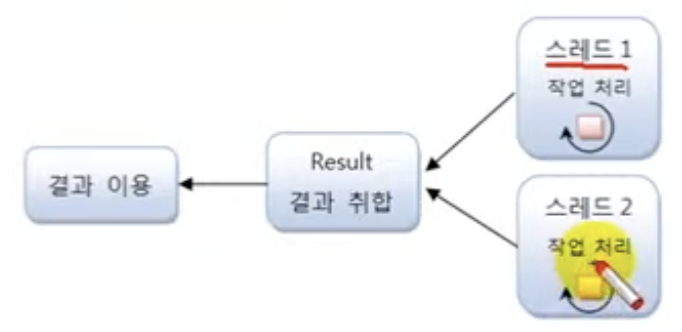
작업 완료 순으로 통보 받기
작업 요청 순서대로 작업 처리가 완료되는 것은 아님!
- 작업의 양과 스레드 스케쥴링에 따라 먼저 요청한 작업이 나중에 완료되는 경우도 발생함
- 여러 개의 작업들이 순차적으로 처리될 필요성이 없고, 처리 결과도 순차적으로 이용할 필요가 없다면,
작업 처리가 완료된 것부터 결과를 얻어 이용하는 것이 좋음
스레드 풀에서 작업 처리가 완료된 것만 통보받는 방법
- poll()과 take() 메소드
1. poll() 완료된 작업의 Future을 가져오고, 완료된 작업이 없다면 즉시 null 리턴
2. poll(long timeout, TimeUnit unit) 완료된 작업의 Future을 가져오고, 없다면 timeout까지 블로킹 됨
3. take() 완료된 작업의 Future을 가져오고, 완료된 작업이 없다면 있을 때까지 블로킹
완료된 작업 통보 받기
- take() 메소드를 반복 실행해서 완료된 작업을 계속 통보받을 수 있도록 함
executorService.submit(new Runnable() {
@Override
public void run() {
while(true) {
try {
Future<Integer> future = completionService.take();
int value = future.get();
System.out.println("처리 결과: " + value);
} catch (Exception e) {
break;
}
}
}
});콜백 방식의 작업 완료 통보 받기
- 콜백이란?
애플리케이션이 스레드에게 작업 처리를 요청한 후 다른 기능을 수행할 동안
스레드가 작업을 완료하면 애플리케이션의 메소드를 자동 실행하는 기법
이때 자동 실행되는 메소드를 콜백 메소드라고 함
블로킹(Future 객체 이용) vs. 콜백(자동적으로 호출)
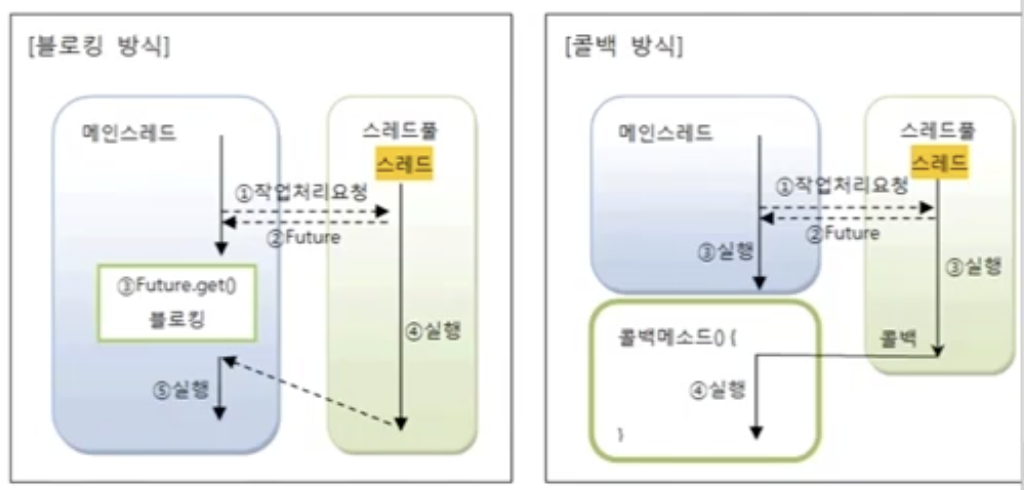
콜백 객체와 콜백 하기
콜백 객체: 콜백 메소드를 가지고 있는 객체
콜백하기: 스레드에서 콜백 객체의 메소드 호출
'2022 여름방학 자바 스터디' 카테고리의 다른 글
| [이것이 자바다] Ch11. 기본 API 클래스 (0) | 2022.08.21 |
|---|---|
| [이것이 자바다] Ch10. 예외 처리 (0) | 2022.08.16 |
| [이것이 자바다] Ch06. 클래스 (0) | 2022.07.28 |
| [이것이 자바다] Ch05. 참조 타입 (0) | 2022.07.15 |
| [이것이 자바다] Ch04. 조건문과 반복문 (0) | 2022.07.14 |
